你有没有想过,用Python3来爬取那些精彩视频教程,让自己的技能提升得飞快?想象你坐在家里,一杯咖啡在手,电脑屏幕上播放着各种编程大师的精彩讲解,是不是很惬意?今天,就让我带你走进Python3爬虫视频教程的世界,一起探索这个神奇的小天地吧!
一、Python3爬虫入门:从零开始
首先,你得有个Python3的环境。别担心,这很简单,去官网下载安装包,按照提示一步步来就OK了。安装好Python后,你还需要一个IDE,比如PyCharm或者VS Code,这样写代码会更方便。
接下来,就是学习Python的基础语法了。虽然爬虫听起来很高级,但其实它就是用Python编写的一些小脚本。所以,掌握Python的基础语法是必不可少的。你可以从网上找一些Python入门教程,比如《Python编程:从入门到实践》这本书,或者B站上的Python入门视频。
二、爬虫工具:库的选择与使用

当你对Python有了基本的了解后,就可以开始学习爬虫工具了。Python中有许多强大的库可以帮助我们实现爬虫功能,比如requests、BeautifulSoup、Scrapy等。
- requests:这个库可以用来发送HTTP请求,获取网页内容。它是爬虫的基础,几乎每个爬虫都会用到它。
- BeautifulSoup:这个库可以用来解析HTML和XML文档,提取我们想要的数据。它就像一个强大的搜索引擎,能帮你快速找到所需信息。
- Scrapy:这是一个更高级的爬虫框架,可以用来构建复杂的爬虫项目。它提供了很多高级功能,比如自动处理JavaScript渲染的页面、分布式爬虫等。
学习这些库的使用方法,你可以参考网上的一些教程,比如《Python爬虫从入门到实践》这本书,或者B站上的相关视频。
三、实战演练:爬取视频教程

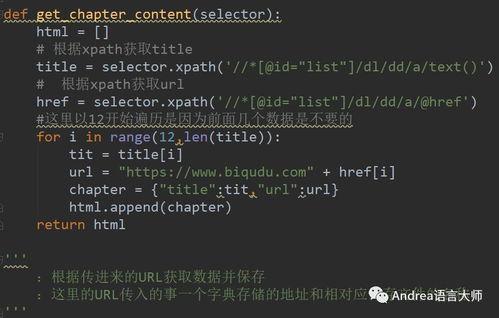
当你掌握了Python爬虫的基础知识和工具后,就可以开始实战演练了。以下是一个简单的爬取视频教程的例子:
1. 确定目标网站:首先,你需要确定一个目标网站,比如慕课网、极客学院等。
2. 分析网页结构:打开目标网站,使用开发者工具查看网页源代码,分析视频教程的网页结构。
3. 编写爬虫代码:根据网页结构,使用requests和BeautifulSoup库编写爬虫代码,提取视频教程的标题、链接、简介等信息。
4. 保存数据:将提取到的数据保存到本地文件或数据库中。
这个过程可能需要一些耐心和细心,但只要你按照步骤来,一定可以成功爬取到视频教程。
四、进阶技巧:处理反爬虫机制
在实际爬虫过程中,你可能会遇到一些反爬虫机制,比如IP封禁、验证码等。这时,你需要掌握一些进阶技巧来应对:
- 代理IP:使用代理IP可以绕过IP封禁,提高爬虫的稳定性。
- 验证码识别:可以使用OCR技术识别验证码,或者使用第三方验证码识别服务。
- 模拟登录:有些网站需要登录后才能访问视频教程,这时你需要模拟登录操作。
这些技巧可以在网上找到相关的教程,或者参考一些爬虫高手的经验。
五、:Python3爬虫视频教程的魅力
通过学习Python3爬虫视频教程,你可以轻松获取各种编程知识,提升自己的技能。在这个过程中,你不仅学会了爬虫技术,还锻炼了自己的编程能力。而且,爬虫技术具有很强的实用性,可以应用于很多领域,比如数据挖掘、舆情分析等。
Python3爬虫视频教程是一个充满魅力的领域,值得你投入时间和精力去探索。相信自己,你一定可以在这个领域取得优异的成绩!